Link to Non-Cached Pages SEO article updated August 2014.
Found this excellent SEO question on a newsgroup “Re: should I reject non-cached sites?” regarding linking to non-cached pages: specifically when a reciprocal link partners links page isn’t cached in Google.
Reciprocal Links to Non-Cached Pages
I run a modest linking scheme on my website and have always had a policy that we would only link to sites that are cached in Google. I’m not so fussy about PageRank at the moment as our link pages are not all ranked.
I’ve had a number of link requests from sites that look pretty well set up but the link page is not cached in Google.
Am I right to reject these as they are no use to my site in terms of IBLs (Inbound Links)? I use the Google toolbar to check the site is cached and have up to now rejected those with no Google cache. Am I rejecting potentially useful sites or doing the right thing?
This is a really good SEO question.
Reciprocal Link Schemes
Let’s dispel an SEO myth quickly, the SEO myth is reciprocal links have no SEO value, basically Google ignores reciprocal links.
This is total SEO BullShit, Google counts all links unless there’s a reason not to (lots of reasons why Google ignores links, being reciprocal per se is not one of them). That’s not to say reciprocal links have loads of SEO value, since you are sending a link back (reciprocating) and most link exchanges will be between similar PageRank webpages the SEO benefits from one link is tiny. Take a look at some Reciprocal Link Exchange Examples to fully understand why these types of links appear to have no SEO value.

The whole point of setting up reciprocal link schemes is to generate backlinks that increase a websites search engine rankings (Google rankings mostly). If a link exchange doesn’t help a sites SERPs long term, from an SEO perspective there’s little point setting up the reciprocal link in the first place. Unless you see another reason to go ahead with the link exchange: for example you see potential in the site or it will generate a lot of click through traffic.
With that in mind when setting up reciprocal links your partners link page should be at least indexed in Google and cached to be sure the page can potentially** pass benefit through text links.
** There are ways like rel=”nofollow” or javascripting links to prevent link benefit passing via a link from an indexed/cached page, so this is one step in the process of checking a reciprocal link partners site out.
The reason for this is obvious, to benefit from their return link Google must know your link exists, if Google doesn’t even spider/index the webpage your text link is on you will not receive any SEO link benefit, but your link partner will gain SEO benefit from your website!!!
That leads us to how to accurately check if a page is indexed and passing link benefit (PR).
How to Use the Google Search Site: Operative
Let’s say I offered you a reciprocal link exchange on my WordPress SEO Package page and you wanted to be sure the webpage your link is on is indexed in Google.
Indexed in Google means the Google’s search engine spider (AKA Googlebot) has gone to the webpage, spidered it’s content and added it to the Google search index, so with the right searches any Google user can find it.
The easiest way is by using the search site: operative in Google. To see if a page is indexed use this search format as a Google search:
site:https://stallion-theme.co.uk/stallion-responsive-theme/
You should see the following in Google for the site: search above:
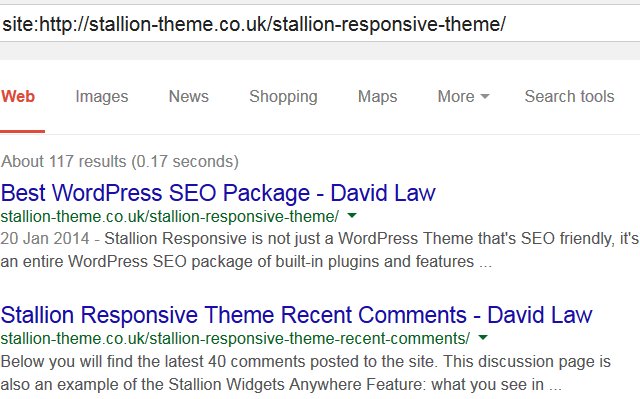
The example above is searching for a highly specific page on this site in Google, you can search an entire site or section/sub-set of the site by using the right search set. Because I use an advanced SEO feature (part of the WordPress SEO package I develop) you’ll note there’s 117 pages indexed in Google for the specific site search, most of these are comments indexed in their own right.
The above sort of URL site: search will tend to find the webpage the URL is for near the top.
Want to try something less specific, try this one:
site:https://stallion-theme.co.uk/responsive/
I don’t have any webpage for the above URL, but all the WordPress categories are found under that URL structure, so the SEO Tutorial category is
https://stallion-theme.co.uk/responsive/seo-tutorial/
When we do a Google site search for “site:https://stallion-theme.co.uk/responsive/” it will find all my sites categories including the Paged ones. Right now (August 2014) there’s 44 category pages indexed in Google.
Want to see the entire domain use.
site:https://stallion-theme.co.uk/
This will list all indexed pages under the domain https://stallion-theme.co.uk/ can give a good indication if the domain is well indexed in Google. Right now (August 2014) my domain has 5,750 pages indexed in Google strongly suggesting there’s no Google indexing issues.
By using different site: searches it allows us to search specific parts of a site narrowing a search to a limited number of indexed pages or to see an overview.
By doing a site: search on a specific page you’ll quickly determine if Google indexed it recently. If you find a page is not found using the site: search it either means it’s a new page (takes time for Google to spider and index a page), Google spidered the page, but decided it doesn’t meet it’s criteria for indexing (happens a lot more often now) or the webmaster blocked spidering/indexing of the page in question (via robots.txt for example).
You can also try searching for the webpage in question. The easiest way to achieve this is find some unique text on the webpage and search for it surrounded by “speech marks” (speech marks means find this “EXACT PHRASE”). If the page is indexed, you should find it for a highly specific search.
On the WordPress SEO Package page is a unique phrase:
“How can Stallion Responsive SEO help my business?”
Search for the above in Google (with the speech marks) and you will find the WordPress SEO package page and of course this page (the text is above), confirming the page is indexed in Google.
Note: if you do a search like the one above and find the webpage is indexed, but scraped (copied) versions of the page are also indexed AND ranking higher than the page you expected to find, be concerned. This can indicate the domain you are considering exchanging links from is carrying a Google penalty (if the content you searched for is owned by them) or they are copying content from other websites.
Search for another unique phrase that is close to the top of the content (more likely to be scraped/copied):
“Stallion Responsive is not just a WordPress Theme that’s SEO friendly”
Now we find multiple domains using this content, but my page is at the top suggesting my webpage is the original source and it’s not penalized by Google. Most of the others have scraped (copied) my webpage or at least the top part (probably via copying the RSS feed).
These are very simple checks that can indicate problems.
At this point if you aren’t particularly SEO/web savvy if you find a page isn’t indexed probably best to refuse the link exchange unless there’s another good reason to proceed.
How to Check if a Page is Cached in Google
The poster of the original SEO question didn’t use the cache: search technique to generate a link to the cached page I’m going to describe below, they used the Google toolbar built in cache link. The Google toolbar is pretty much dead now, it’s not been developed for FireFox or Google Chrome in years and only available for IE. so I’ve removed the Google toolbar instructions and replaced them with general ways to check a Google cache.
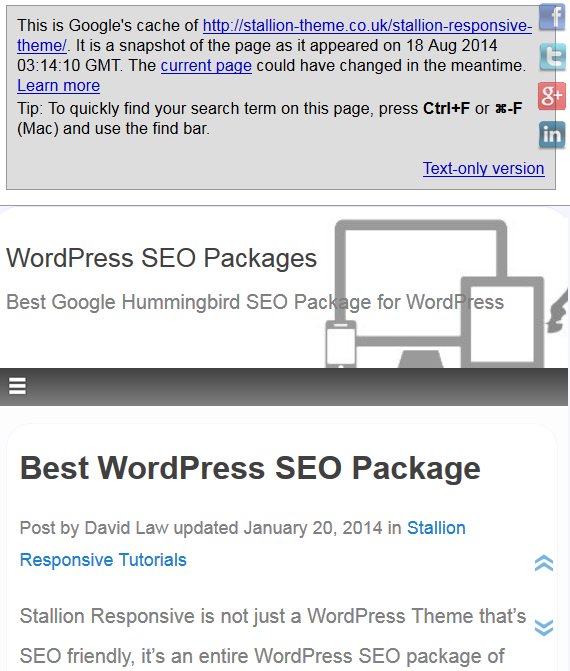
We’ve found the page is indexed, next we check it’s cache using the following search format:
cache:https://stallion-theme.co.uk/stallion-responsive-theme/
You should find a Google result something like this:
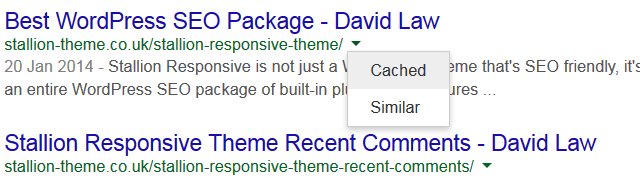
You can also check a Google cache directly from the search result, on the earlier site: search results each listing has a a small down arrow to the right, click it and see the Cached link.
If you see a Google cache like the one shown above (first image) you know Google is indexing the webpages content.
To summarise, a linking page should be indexed (site: search) and cached (cache:url or site:url search click Cached link) to be reasonably confident Google is spidering, indexing AND ‘seeing’ the same page you are.
When to Link to Non-Cached Pages
There are legitimate reasons for some webpages not having a Google cache, some webmasters set a page to no-cache so search engine visitors etc… always see the very latest version of their content. Obvious reasons for this include frequently updated content, say a news site or stock quote site. With a site like this there should be no problems accepting link exchanges, your website will benefit from the text link.
There’s several ways to specify no-cache including adding the following to the head of a page-
<META HTTP-EQUIV="CACHE-CONTROL" CONTENT="NO-CACHE">
and/or
<META HTTP-EQUIV="PRAGMA" CONTENT="NO-CACHE">
If a possible reciprocal link partners link pages are indexed (can find via a site: search) but not cached check if something like the above is present within the head of the page. There’s also server side no-caching that’s not so easy to spot.
Be a little more wary of webmasters that use no-cache as it’s part of a few SEO blackhat techniques like cloaking: you present one page (highly optimized page) to search engine spiders and show sales content to real visitors. A visitor checking the cache of a page like this will spot the discrepancy and maybe report the site to the search engines, by using no-cache no one gets to see what the search engines actually see (there are ways to check like spoof your user agent to Googlebot, but that’s beyond this SEO tutorial)
Cloaking like this can also be achieved for a specific visitor (unlikely, but…). If the potential reciprocal link partner knows your IP address (static IP obtained via emails discussing a potential link exchange) they can cloak their links pages to show your links when and only when you visit the site. If you check the cache though you’ll notice the lack of your link… and so when this technique is used they tend to no-cache the pages. Though they’ll use server side no-cache not the meta ones listed above.
How To Trick Webmasters to Link
There’s a similar blackhat SEO technique to the one above to try to trick webmasters into believing a website is linking to them making it more likely they will link back. I use the concept on the Privacy Policy page, so I can use one page for multiple domains (not trick other webmasters to link here).
Click the privacy link above and note the top line reads:
Privacy Policy for the Website https://stallion-theme.co.uk/reciprocal-links-to-non-cached-pages/
Now click the privacy link from the home page (it’s within the footer) and note the top line now reads:
Privacy Policy for the Website https://stallion-theme.co.uk/
Where ever the visitor comes from determines the URL shown. Could easily add the URL into a clickable link.
Look at the Google cache for the page:
cache:https://stallion-theme.co.uk/privacy-policy/
To trick webmasters into believing they have a link from my site I’d temporarily add a link to their website and visit the link, this would add a reference in their logs and many log analysis programs add clickable links. When they visit the site from the link it generates a link that looks like I’m linking to them. A little bit of PHP and can even strip the URL shown back to only load the main part of the domain, so a visit from “example.com/some-where-in-logs.html” is stripped to “example.com/” so it looks like a home page link.
To check for this type of blackhat SEO trick simply load the URL in a browser window by copying and pasting the URL or check it’s cache. Copy and paste https://stallion-theme.co.uk/privacy-policy/ into your favorite browser, note the text now lacks a URL confirming no link exists.
I’ve not provided any details how to achieve this blackhat SEO link building technique because it’s unethical tricking webmasters to add reciprocal links in the belief you linked to them first.
Be very careful with webmasters that use no-cache, ask yourself does that sites content really warrant the use of no-cache? If not I wouldn’t risk it.
David Law
Website - SEO Gold


Links from Cached WebPages
Nice post.
It’s worth pointing out that being cached and indexed are not the same thing. I have a few websites where I’ve removed all the pages from Google’s cache yet all pages remain in their index. The links still count, as long as the page is indexed.
I agree though, that in general it’s a better plan to look for both cached and indexed pages, just to be on the safe side.
Links from Cached WebPages
Cached and Indexed Links
Defenitely a nice post. I also agree and i also think it is critical to look for both cached and indexed pages.
It’s easy to forget that, but it is very important for getting good SERP’s.
Google Cached vs Google Indexed
Hi Darren and Marcel,
You both make good points, this is the first draft of the SEO article and is aimed mostly towards those who are not as SEO savvy as SEO consultant are (or should be, some don’t have a clue!!).
I plan to continue the article and explain how pages can legitimately be indexed, but not show a Google cache and still pass full link benefit. For example webmaster who set no cache results in an indexed page with no Google cache that will pass full link benefit.
The difficulty is explaining these technical issues without getting bogged down in technical jargon. Which is why I stopped at where I did (the “To summarise” bit) giving me time to think how best to approach the rest of the article :-)
Thanks for the comments.
David
Google Cached vs Google Indexed
Reciprocal Links to Non-Cached Pages
I was the original poster of the question so very chuffed to see such a comprehensive reply as a result.
Thanks for taking the time to answer what I thought was a valid question.
Shame it didn’t get such a good response in the newsgroup!
Very informative!
Good SEO Questions
Hi Ian,
The reason I created the SEO article was because I also thought it was a very good SEO question and should have resulted in a better set of responses.
It’s a shame as the newsgroup alt.internet.search-engines used to be the sort of place where both those new and old to SEO could get answers to SEO queries like yours, now there’s a lack of detailed SEO knowledge with most regular posters (some are very informative in other areas, just not SEO).
Was the reason I stopped posting their on a regular basis.
Anyway, glad I helped answer your SEO question.
David
Good SEO Questions
SEO Newsgroups
Dave,
Very nice post. Yes, the NG is becoming less and less infomative. I post a lot less, so when most of the regulars don’t post as often you find that the information is slacking.
I just go there just briefly to look at times. I have just been so busy lately.
BTW I owe you an email I know, I am becoming like you on the busy side and not getting around to my emails.:-) Doesn’t mean I don’t think about ya and come around to see how you are doing.;-)
Stacey
SEO Newsgroups